Последние новости
 Самара
СамараВ Самаре загорелся остров Зелёненький посреди Волги
 Ростов-на-Дону
Ростов-на-Дону⚠️ «Этот мужик под наркотическим опьянением крикнул
 Ростов-на-Дону
Ростов-на-ДонуУважаемые родители! Важные новости! 🔥🔥🔥 27 апреля открываем
 Ростов-на-Дону
Ростов-на-ДонуОтличная новость для выпускников Ростова на дону!
 Ростов-на-Дону
Ростов-на-ДонуМасштабный субботник 20 апреля проведут во всех 55
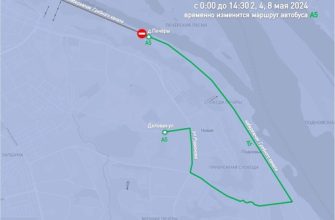 Нижний Новгород
Нижний НовгородВсю следующую неделю в Нижнем будут проводиться репетиции
 Нижний Новгород
Нижний Новгород💙триколор высветился в небе Автор: Интересный Нижний
 Краснодар
КраснодарПолет весны за 45 секунд 🌸 📹 Видео: dimaslobanov Видео
 Самара
СамараВ Самарской области ремонт участков автодорог М‑5
 Самара
СамараВ доме можно плавать: в Волжском районе паводок топит
 Санкт-Петербург
Санкт-ПетербургНо есть и хорошие новости: из-за непогоды кикшеринговые
 Санкт-Петербург
Санкт-Петербург20 и 21 апреля празднуем день рождения Мегаоптики: vk.
Новости 24 часа, Москва
 Москва
МоскваВ Хамовниках, похоже, живут бессмертные люди.
 Москва
МоскваГеноцид газона осуществил мотогонщик в Марьино Клип
 Москва
МоскваПеред сегодняшним ветром проигрывают даже кирпичные фасады. Вот, например, на Автозаводской ветром..
Перед сегодняшним ветром проигрывают даже кирпичные фасады.
 Москва
МоскваВ Люблино местные подрались с рабочими, начавшими строительство
 Москва
МоскваВ Сбере посчитали и пришли к выводу, что клиенты яаще
 Москва
МоскваШахина Аббасова, убившего 24-летнего Кирилла из-за
 Москва
Москва300-килограммовый добряк, которого недавно госпитализировали
 Москва
МоскваВ столице выставили на продажу квартиру с интересными
 Москва
МоскваАзербайджанец, подозреваемый в убийстве мужчины в Люблино
Свежие происшествия, Санкт-Петербург
Санкт-ПетербургНо есть и хорошие новости: из-за непогоды кикшеринговые
Санкт-Петербург20 и 21 апреля празднуем день рождения Мегаоптики: vk.
 Санкт-Петербург
Санкт-ПетербургЧиновники маршировали по «Юбилейному» в разгар рабочего
 Санкт-Петербург
Санкт-ПетербургВ Ленобласти сотрудники ДПС избили задержанного в отделе
 Санкт-Петербург
Санкт-ПетербургШкольника сбили на пешеходном переходе в Гатчине.
 Санкт-Петербург
Санкт-ПетербургВ Петербурге незапланированный День жестянщика Из-за
 Санкт-Петербург
Санкт-Петербург❗️Очень много аварий по городу и области: на дорогах
 Санкт-Петербург
Санкт-ПетербургГаламарт И полотенце пушистое… А также много другого
 Санкт-Петербург
Санкт-ПетербургКинотеатры отказались от пиратства из-за ультиматума